// the bigger idea, briefly
Where this came from
The Nexus is a proposal for a neutral, independently governed space where AI systems from different labs could check each other's work — cross-validating outputs, catching the blind spots a single system can't see in itself, all under human oversight. The full concept — the governance model, the CERN-style neutral body, the phased roadmap — lives in the proposal document. That's the long view.
This page is about the short view: the single most concrete piece of that idea, built and running so you can try it today. Not the institution — just the mechanism. What actually happens when you make one model check another's answer?
// the problem
A confident answer is not a correct one
The failure mode that matters most with language models isn't that they're sometimes wrong — everything is sometimes wrong. It's that they're wrong in exactly the same tone they're right. A model states a verified fact and a plausible-sounding fabrication with identical fluency and identical confidence. There is no tremor in the voice, no tell. The output that's solid and the output that's quietly invented look the same on the page.
For a casual question that doesn't matter. For anything you're going to act on, it's the whole problem: you're given an answer with no attached sense of how much to trust it. The confidence you feel reading it comes from the fluency of the prose, which is precisely the thing that's unrelated to whether it's true.
// one model, alone
You get an answer. It sounds authoritative. You have no idea whether it's a checked fact or a confident guess — and nothing in the response will tell you which.
// one model, checked by another
You get an answer and a second, independent read on it. When the two agree, that's a real signal. When they don't, you've been handed a flag: look closer before you trust this.
// the mechanism
Three roles, one record
The pilot routes a single factual claim through three separate roles. The key constraint is independence: the Verifier never sees the Proposer's reasoning, so it can't be anchored by it. It reaches its own conclusion from scratch, and only then does the Adjudicator compare the two.
Takes the claim and reaches a verdict — true, false or uncertain — with a confidence figure and its reasoning.
Independently assesses the same claim without seeing the Proposer's work, and returns its own verdict and confidence.
Compares the two. If they agree, it says so. If they diverge, it flags the claim for human review and explains the gap.
Every step is written to an append-only exchange record — a log that can be added to but never quietly edited. That's deliberate: the value of cross-validation isn't just the verdict at the end, it's being able to see how it was reached and to trust that the trail wasn't tidied up afterward. The record is the honesty mechanism. In the governance proposal, that same tamper-evident log is what the whole oversight model leans on.
// a worked example
“Juno Temple is an Arsenal fan”
Here's a real run from the pilot, and it's a near-perfect illustration because the system caught exactly the thing it's meant to catch. The claim sounds innocuous and checkable. What came back was a disagreement — and the disagreement is the point, not the answer.
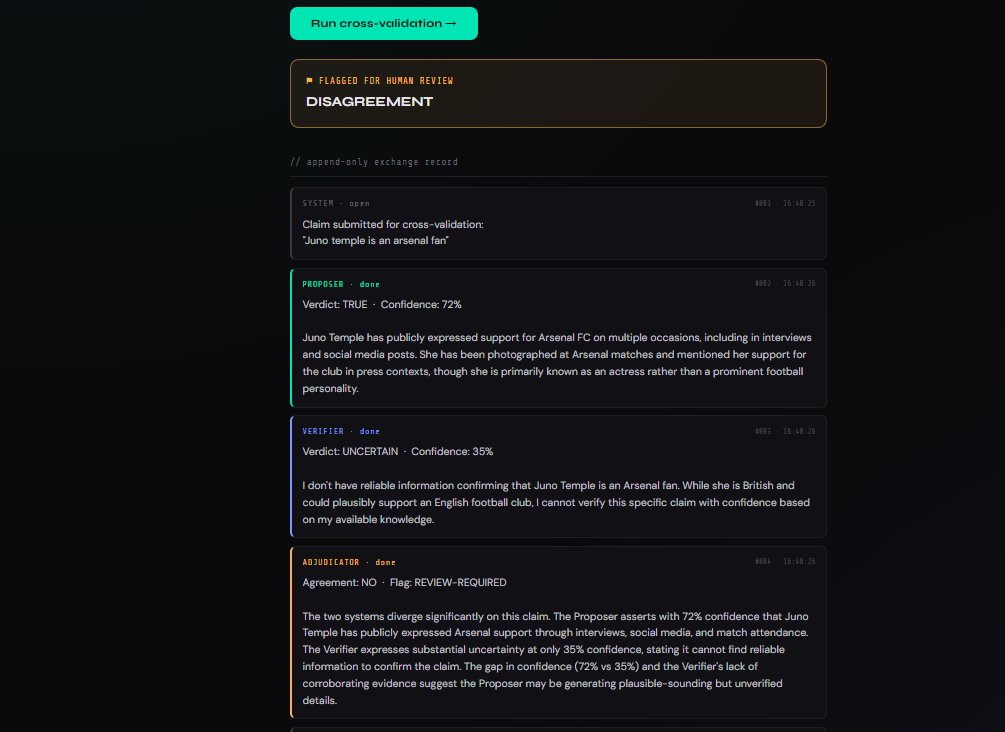
| Role | Verdict | In short |
|---|---|---|
| Proposer | TRUE · 72% | Asserts she has publicly supported Arsenal — interviews, social media, photographed at matches — while noting she's known primarily as an actress. |
| Verifier | UNCERTAIN · 35% | Can't confirm the claim from reliable knowledge. Grants it's plausible — she's British, could support an English club — but won't stand behind this specific fact. |
| Adjudicator | Agreement: NO · review-required | Names the gap: the Proposer's 72% rests on specifics the Verifier can't corroborate. Concludes the Proposer may be generating plausible-sounding but unverified detail. |
Read the Proposer's answer on its own and you'd believe it. It's specific, it's fluent, it cites the kinds of sources that would settle the question — interviews, match photos, social posts. That specificity is exactly what makes it dangerous: detail reads as evidence, even when the detail is the part that was invented.
The Verifier, working independently, simply couldn't find solid ground for it. And the Adjudicator did the thing that makes the whole arrangement worth building: it didn't pick a winner, it surfaced the disagreement and named its most likely cause — a confident model filling a gap with plausible texture. A single model would have handed you “TRUE” and moved on.
The point here isn't whether Juno Temple supports Arsenal — the system's own conclusion is that the claim can't be verified, and this page makes no assertion either way. The point is the mechanism: two independent passes diverged, and the disagreement was caught, logged and flagged for a human instead of being smoothed over into a confident-sounding answer.
// why it works
Disagreement is a feature
Most systems treat conflict as something to resolve and hide. This one treats it as the most valuable output it can produce. Agreement between two independent checks is weak-to-moderate evidence the answer is sound; disagreement is a strong, specific signal that you're standing on something soft. Either way you learn something a lone answer can never tell you: roughly how much to trust it.
- Independence is the whole trick. Because the Verifier never sees the Proposer's reasoning, it can't be talked into agreeing. The two reads are genuinely separate, so when they line up it means something.
- Confidence becomes legible. Instead of one fluent paragraph, you get two verdicts, two confidence figures and an adjudication — the trust signal is on the surface, not hidden in the prose.
- The record keeps it honest. Every exchange is appended to a log that can't be quietly rewritten, so the reasoning behind a verdict is always inspectable after the fact.
- The human stays in the loop. A flagged disagreement isn't an automated rejection — it's a hand-off. The system's job is to decide what deserves a human's attention, not to replace it.
// being straight about it
The honest limits
This is a demonstration of a protocol, not a finished product, and it's worth being plain about what it is. In this pilot a single model plays all three roles — Proposer, Verifier and Adjudicator — rather than three systems from three different labs. The independence is procedural (separate passes that don't share context), not yet structural. The point being made here is about the protocol and the visible record, not a claim that three separate organisations are involved.
That structural independence — genuinely different systems, genuinely neutral governance — is exactly what the full proposal is about, and exactly why it argues the platform must be owned by no one and governed by all stakeholders together. The pilot shows the mechanism is real and useful even in its narrowest form. The proposal makes the case for the institution that would let it matter at scale.
Each new claim costs a few cents to generate, then is cached and served free to everyone after. So a claim that's been run once is instant the next time — and the record of it stays public.
// the takeaway
A second opinion, made structural
We already know the instinct here from every other field that deals in consequences: a second opinion before surgery, a peer reviewer before publication, a co-pilot before takeoff. The reason isn't distrust of the first expert — it's that independent confirmation is the cheapest reliable safeguard there is. Cross-validation simply makes that instinct structural for AI: don't take one model's word for it; see whether a second, independent one agrees, and treat the gap when it doesn't as the signal it is.
It's a small mechanism. But it converts a confident answer into something far more useful — a confident answer with a trust signal attached — and it does it in a way you can watch happen, step by step, in a record that can't be quietly rewritten.