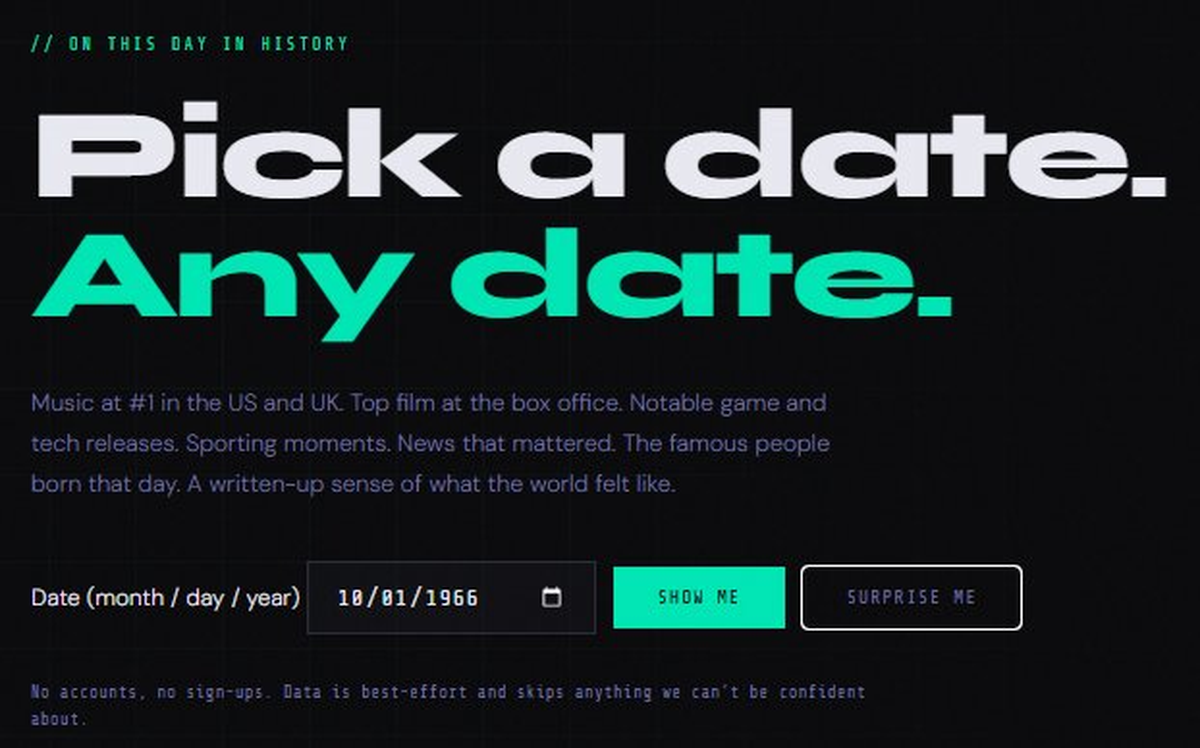
// the idea
One page. Three timeframes.
The premise: pick a date — your birthday, your kid's birthday, the day you got married, an idle Wednesday in 1972 — and get a single page that describes what the world was like around then. Not just one slice. Three.
The calendar day gives you the famous people born on it across all of history (split into 'alive by your chosen date' and 'born later, same calendar day' — so a 1970 lookup sees Carole King first and Michael B. Jordan in the second list), plus the news and sport that actually happened on that exact date. The month gives you the chart-toppers across the US and UK. The year gives you the top films and notable games/tech releases. And a closing paragraph in the voice of a quiet historian pulls all the threads together.
The layered framing is on purpose. Each section uses the timeframe its data honestly supports rather than pretending every piece of trivia is day-exact. The interesting question was whether AI plus a handful of free public datasets could pull that scatter together into one coherent page, for any date, on demand, for fractions of a cent.
// the architecture
A small PHP file doing real work
The whole back end is one PHP file on the same GoDaddy hosting as the rest of cyber-wyse. No new accounts, no Node servers, no Cloudflare Workers. When a visitor picks a date, the page calls api.php, which orchestrates four data sources in parallel:
Subsequent visits to the same date skip everything and serve the cached JSON in milliseconds, free of charge. A typical date generates once at a cost of around three cents, then lives forever in the cache.
// the data sources
Real data, where it exists
The accuracy of the page depends on where each piece of information comes from. Wherever a clean public API exists, the data comes from there directly — not from a language model's memory.
-
Wikipedia REST API
The
feed/onthisday/birthsandfeed/onthisday/eventsendpoints return Wikipedia's own ranked lists of notable people born and major events on any calendar date. Free, no auth required, beautifully clean JSON. - Billboard Hot 100 The mhollingshead/billboard-hot-100 repository keeps a JSON file for every weekly Hot 100 chart from August 1958 to present. The script pulls each chart in the user's chosen month and consolidates consecutive weeks where the same single held #1.
- Claude Sonnet 4.6 For sections without a clean dataset — UK Singles, US and UK Albums, top films of the year, notable games and tech releases — Claude is asked for month-scoped or year-scoped lists. This works far better than asking for "the #1 on this exact week", which Claude is prone to getting wrong; month-level recall is much stronger.
- The Scene paragraph Once every other section is filled with verified facts, Claude writes a 70-110 word closing paragraph pulling the disparate threads into a coherent sense of the moment. It only has to write — not remember — which is the part it does well.
The first version asked Claude for everything, including specific weekly chart positions. The results were plausible but routinely wrong — Claude would confidently put a song at #1 the wrong week, or invent a film that didn't actually top the box office. Switching the music section to real Billboard data, and the births to the Wikipedia API, was the moment the page went from charming-but-untrustworthy to genuinely useful.
// the births trick
Born by, and born later
The "famous birthdays" section is split into two lists. The first — Born on this day — shows people born on the exact calendar date who were already alive when the chosen date arrived. The second — Born later on this date — shows people who share the same calendar day but were born after the chosen year.
So for 9 February 1970, the first list gives you Carole King, Joe Pesci, Mia Farrow and Alice Walker. The second list gives you Michael B. Jordan, Tom Hiddleston and Charlie Day — people who share that calendar birthday but hadn't been born yet on the chosen date.
It's a small distinction but it sidesteps the "your birthday twin is younger than you" paradox that most on-this-day sites just shrug at. Both lists are useful: one tells you who shared the world on that day, the other tells you who shares your calendar.
// the deploy story
The simplest possible setup
The hard constraint was that I wasn't willing to spin up new infrastructure for this. No Cloudflare Workers (no new accounts). No Python scripts (none of my hosting runs scripts). Everything had to live on the GoDaddy shared hosting cyber-wyse already pays for.
This turns out to be enough. PHP with cURL is enabled by default on GoDaddy. The whole project deploys as five files dropped into a folder — index.html, style.css, app.js, api.php, and a config.php with the API key — plus an auto-created cache/ directory. No build step, no framework, no migration. Editing the model or rate limit is one line in config.php.
// what it costs to run
A few cents per unique date, then nothing
Each new date the site generates costs around three cents in Claude API spend — one Sonnet 4.6 call processing the pre-fetched authoritative data and writing the bits Claude is responsible for. The Wikipedia and Billboard calls are free.
Every cached date thereafter is served from the JSON file at zero cost. A modest-traffic year, where visitors look up maybe 1,000 unique dates, costs around $25 in API spend. There's a rate limit of 30 new generations per IP per hour, which means no one can run up a bill by hammering the picker.
// what's next
Things to layer in later
The current scope is deliberately tight. There's room to grow if it earns it: a proper print-broadsheet PDF for downloading as a gift, more granular weekly film data for post-1980 dates where it exists, a "this year" overview page collecting the most-viewed dates from a given decade, and possibly a small premium tier offering personalised printed posters.
For now the page does what it should: pick a date, get a layered snapshot, share or print it if you want, no friction in either direction.